Dans cet article, nous nous intéressons à l’utilisation des réseaux de neurones convolutifs dans le cadre de la détection d’objet. Plus précisément, nous allons utiliser l’algorithme MobileNet-SSD avec OpenCV afin de mettre en place un détecteur d’objet.
MobileNet est un réseau de neurones convolutifs, développé par Google, permettant de classifier 21 types d’objets et présentant des avantages tels que légèreté, rapidité et précision.
Ce réseau de neurones est associé au réseau de neurones Single Shot Multibox Detector (SSD) permettant d’identifier toutes les zones dans l’image présentant un élément à classifier.
La combinaison de MobileNet et de SSD permet d’obtenir une méthode rapide et efficace de détection d’objets basée sur l’apprentissage profond.
Le modèle que nous utilisons est une implémentation sous Caffe entrainée par Chuangi305.
En bas de cet article, vous trouverez un bouton pour télécharger le code source, ainsi que modèles entraînés, utilisés dans cet article.
Reconnaissance d’objet avec MobileNet et OpenCV
Nous commençons par importer les bibliothèques nécessaires pour le fonctionnement de notre programme.
import numpy as np import argparse import cv2
Puis nous analysons aux lignes 5 à 10 les arguments donnés par l’utilisateur lors de l’appel du programme
ap = argparse.ArgumentParser()
ap.add_argument("-i" ,"--image", required=True, help="Chemin vers l'image à analyser")
ap.add_argument("-p", "--prototxt", required=True,help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--modele", required=True,help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confiance", type=float, default=0.2,help="probabilité minimale pour filtrer les détections faibles")
args = vars(ap.parse_args())Nous initialisons ensuite les labels des différentes classes, ainsi que les couleurs pour les représenter.
CLASSES = ["arriere-plan", "avion", "velo", "oiseau", "bateau", "bouteille", "autobus", "voiture", "chat", "chaise", "vache", "table","chien", "cheval", "moto", "personne", "plante en pot", "mouton", "sofa", "train", "moniteur"] couleurs = np.random.uniform(0, 255, size=(len(CLASSES), 3))
Maintenant que les représentations des classes sont initialisés, nous pouvons charger le modèle (l.18), ainsi que l’image que nous voulons utiliser (l.19)
net = cv2.dnn.readNet(args["prototxt"], args["modele"]) image=cv2.imread(args["image"])
La fonction cv2.dnn.readNet() d’OpenCV permet de charger un réseau d’apprentissage profond. Elle prend en entrée le fichier de configuration du réseau, ainsi que le modèle pré-entrainé. Elle permet de détecter automatiquement le framework utilisé et il est alors possible de donner en argument des fichiers Caffe, TensorFlow, Torch, DarkNet, …
Par la suite, nous récupérons la taille de notre image d’entrée, puis nous réalisons une transformation à cette image, afin quelle soit au bon format pour appliquer le modèle :
(h, w) = image.shape[:2] blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300),127.5)
Les questions que vous devez vous posez est qu’est ce que fait cette fonction et d’où viennent ces valeurs ?
Explications sur la fonction blobFromImage()
La fonction cv2.dnn.blobFromImage() permet de réaliser les prétraitement sur une image afin de pouvoir obtenir une classification correct.
Les opérations de prétraitements régulièrement utilisées sont la soustraction de la moyenne de l’image et la multiplication par un facteur d’échelle permettant la normalisation.
Les options de ces prétraitements doivent être identiques à ceux utilisés lors de l’entrainement du modèle. Nous pouvons donc les retrouver dans le dépôt github du modèle MobileNet-SSD, comme par exemple dans la fonction preprocess() du programme demo.py.
Le facteur d’échelle utilisé, lors de l’entrainement, est de 0.007843, et la valeur moyenne que nous devons soustraire est de 127,5. Enfin l’image que nous attendons
Les images que voulons traiter doivent être de la même taille que les images utilisées pour l’entrainement du modèle à savoir 300×300. Ce que nous spécifions en 3ème argument.
Nous donnons ensuite l’image pré-traitée comme entrée du réseau de neurones (l. 24), puis nous réalisons les calculs des différentes couches du réseau de neurones (l. 25). Nous obtenons un tableau comprenant les résultats de la dernière couche du réseau.
net.setInput(blob) detections = net.forward()
Affichage des résultats
Un des arguments que nous avons défini lors de l’appel du programme est la confiance, permettant de conserver les résultats les plus sûrs.
Pour chaque objet détecté (l. 27), nous récupérons sa valeur de confiance (l. 28), afin de ne garder que les détections suffisamment sûres (l. 29).
Par la suite, nous récupérons l’index de la classe correspondant à l’objet détecté (l. 30) ainsi que ses coordonnées (l. 31) que nous convertissons en entier (l. 32).
for i in np.arange(0, detections.shape[2]):
confiance = detections[0, 0, i, 2]
if confiance > args["confiance"]:
index = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")Il ne nous reste plus qu’à afficher les détections :
On commence par créer les labels que l’on affichera à coté des détections (l. 34). Ces labels sont composés du nom de l’objet, ainsi que le score de confiance que nous arrondissons à 2 décimales après la virgule.
Puis, nous en profitons pour préparer la position de ce label (l. 35). Nous souhaitons qu’il apparaisse en haut à gauche du rectangle encadrant, sauf dans le cas où l’objet détecté correspond à l’image en elle-même. Dans ce cas, le label sera positionné 20 pixels sous le coin en haut à gauche.
Enfin, nous traçons le rectangle encadrant (l. 36), le label (l.37) et nous affichons l’image traitée (l. 38-39).
label = str(CLASSES[index]) +" : " + str(round((confiance * 100),2))
y = startY - 20 if startY - 20 > 20 else startY + 20
cv2.rectangle(image, (startX, startY), (endX, endY),COLORS[index], 10)
cv2.putText(image, label, (startX, y),cv2.FONT_HERSHEY_SIMPLEX, 5, COLORS[index], 5)
cv2.imshow("Frame", image)
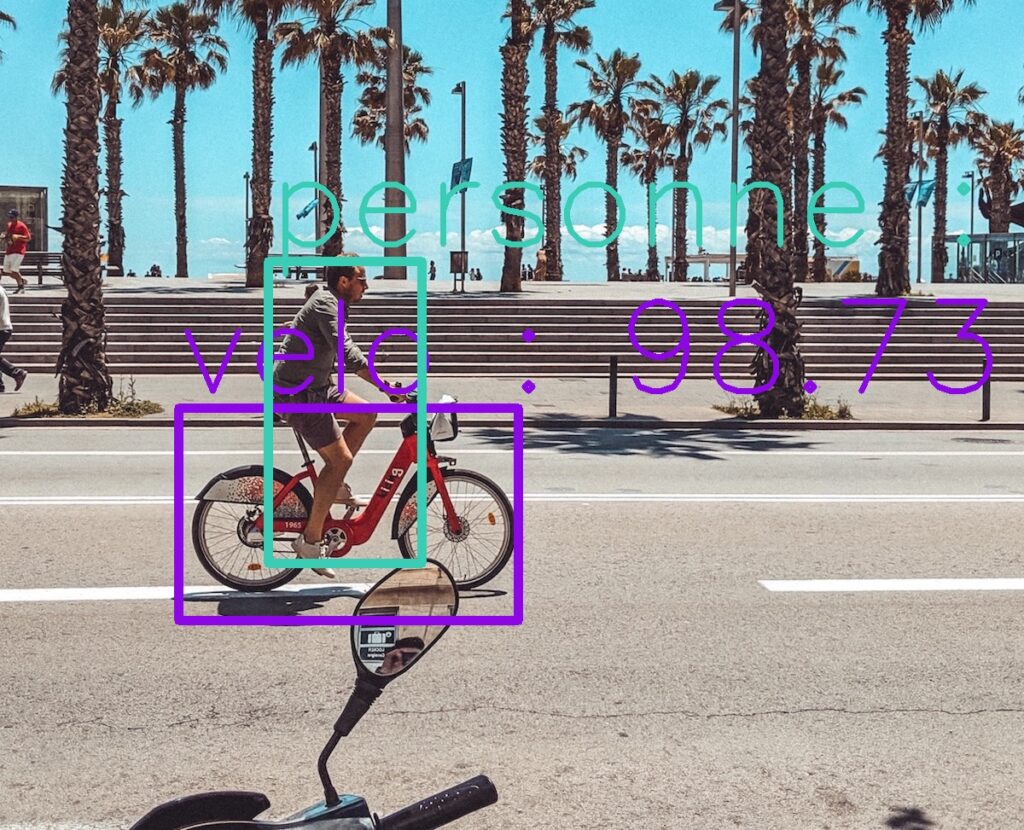
cv2.waitKey(0)Résultats
Il ne nous reste plus qu’a tester notre programme sur quelques images :
python3 reconnaissance_objet.py -i image.jpg -p MobileNetSSD_deploy.prototxt.txt -m MobileNetSSD_deploy.caffemodel




Téléchargement des fichiers
Si vous souhaitez utiliser tester ce programme, je vous invite a télécharger les fichiers en cliquant sur le lien ci-dessous 🙂
Reconnaissance d'objet (894 téléchargements )


1 commentaire
Reconnaissance d’objets en temps réel avec MobileNet – Pymotion · 2 décembre 2025 à 12h33
[…] avons vu dans un précédent article comment utiliser l’algorithme MobileNetSSD pour la reconnaissance d’objet dans une image. Dans […]