Le classificateur en cascade de Haar est l’une des premières et des plus connues des méthodes de détection d’objet. Publié en 2001 par Paul Viola et Michael Jones, l’article Robust Real-time Object Detection est devenu une référence dans le domaine de la détection d’objet.
Dans cet article, nous allons dans un premier temps, étudier les grandes lignes de cette méthode. Puis, nous allons mettre en œuvre cette méthode afin de détecter différents types d’objet.
Fonctionnement des cascades de Haar
La méthode de Viola-Jones consiste à parcourir une image à l’aide d’une fenêtre glissante (de 24 x 24 pixels dans l’algorithme original) et de déterminer si un visage y est présent. Cette méthode consiste à parcourir l’ensemble de l’image en calculant un certain nombre de caractéristiques dans des zones se chevauchant. Elle a la particularité d’utiliser des caractéristiques très simples mais très nombreuses.
Caractéristiques pseudo-Haar
Plutôt que de travailler directement sur les valeurs de pixels, Viola et Jones proposent d’utiliser des caractéristiques très simples : les caractéristiques pseudo-Haar, qui doivent leur nom à leur similarité avec les ondelettes de Haar. Ces caractéristiques sont calculées par la différence des sommes de pixels de deux ou plusieurs zones rectangulaires adjacentes.

Pour chaque caractéristique, on calcul la somme de pixels délimités par la zone sombre soustrait à la somme des pixels délimités par la zone claire. Afin d’accélérer le calcul de la somme des pixels dans chaque zone, Viola et Jones utilisent une image intégrale. Ainsi, il est possible de calculer la somme des pixels dans une zone avec seulement quatre accès à l’image intégrale.
Cascade de classificateur
Le terme cascade dans le nom du classificateur signifie qu’il est le résultat de plusieurs classificateurs plus simples (que l’on appelle stages) qui sont appliqués successivement sur une région d’intérêt jusqu’à ce qu’un des stages échoue où qu’ils soient tous validés. L’idée est de rejeter les zones ne contenant pas l’objet avec le moins possible de calculs. Le premier classificateur est donc le plus optimisé et permet de rejeter rapidement une zone si l’objet recherché ne s’y trouve pas. Si potentiellement l’objet s’y trouve, alors le deuxième classificateur est utilisé et ainsi de suite jusqu’au dernier.
Dans la vidéo suivante, nous pouvons voir une visualisation des cascades de Haar sur une image.
Détection d’objet avec les cascades de Haar
Les classificateurs
L’entraînement d’un classificateur est une étape longue. Il est nécessaire de réunir et d’annoter un grand nombre d’image contenant l’objet à détecter. Heureusement, il existe des classificateurs déjà entrainés disponibles dans les fichiers d’OpenCV. Vous pouvez les retrouver dans le dossier « opencv/data/haarcascades/ », ou bien en les téléchargeant depuis le github d’OpenCV.
Parmi ceux-là, nous pouvons trouver des détecteurs pour:
- Les yeux : haarcascade_eye.xml
- Les têtes de profil : haarcascade_profileface.xml
- Les sourires : haarcascade_smile.xml
- Les visage : haarcascade_frontalface_alt.xml
- Les torses : haarcascade_upperbody.xml
- Des corps entiers : haarcascade_fullbody.xml
- Des têtes de chat : haarcascade_frontalcatface.xml
Nous allons maintenant, voir comment nous pouvons utiliser ces classificateurs.
Le code
Nous pouvons maintenant passer au code qui se révèle assez simple.
import cv2
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt.xml')
img = cv2.imread('image.jpg')
faces = face_cascade.detectMultiScale(img, scaleFactor=1.3, minNeighbors=5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()Nous chargeons la bibliothèque OpenCV à la ligne 1, puis nous chargeons notre classificateur à la ligne 3. Dans mon cas, le fichier xml est situé dans le dossier contenant le programme. Si ce n’est pas le cas, veillez à bien spécifier le chemin. Enfin, nous chargeons l’image à traiter à la ligne 5.
Maintenant que tout est prêt, nous pouvons donner notre image en entrée au classificateur à la ligne 6. La fonction detectMultiScale permet de détecter les objets dans l’image en utilisant différentes échelles. Afin d’effectuer les testes à différentes échelles, le calcul des caractéristiques pseudo-Haar est réalisé sur des images de tailles décroissantes. Le paramètre scaleFactor permet de définir de combien réduire la taille de l’image à chaque itération. Le paramètre minNeighbors permet de définir à partir de combien de détection voisine doit avoir une zone candidate pour être retenu.
Enfin, pour chaque objet détecté (L. 8), nous traçons le rectangle encadrant (L. 9). Puis nous affichons l’image (L.11-13).
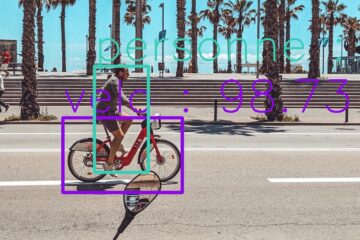
Quelques tests
Essayons maintenant d’appliquer différents classificateurs sur différentes images. Pour chaque image ci-dessous, le nom du classificateur ainsi que le scaleFactor (sf) sont indiqués.





Nous pouvons remarquer que le choix de la valeur de ScaleFactor influe fortement sur le résultat de la détection. Dans le cas de l’image présentant un groupe de quatre personnes, un SF de 1.2 permet de détecter 3 personnes sur 4, un SF de 1.01 permet de détecter les 4 visages mais génère 2 faux positifs.
Afin d’améliorer la détection, il est possible d’utiliser plusieurs classificateurs. Sur la dernière image, un détecteur de visage et un détecteur d’œils sont utilisés. La présence des deux yeux confirme qu’il s’agit bien d’un visage.
Nous avons vu dans cet article comment détecter des objets grâce aux cascades de Haar. Les classificateurs proposés par OpenCV permettent de détecter différentes catégories d’objet. Dans cet article, nous avons mis en œuvre des classificateurs permettant de détecter des têtes de chats, des visages, et même certaines partie des visages.


0 commentaire